![]()
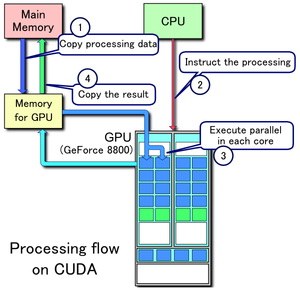
In this post I have implemented Mergesort on the GPU with cuda. . If you don’t know, CUDA is a programming model designed for using your GPU for parallel computation. GPUs are optimized for running the same instructions on multiple threads at the same time.
Algorithm
Merge Sort is a Divide and Conquer algorithm. It divides input array into two halves, calls itself for the two halves and then merges the two sorted halves. The merge() function is used for merging two halves. The merge(arr, l, m, r) is the key process that assumes that arr[l..m] and arr[m+1..r] are sorted and merges the two sorted sub-arrays into one. See following C implementation for details.
MergeSort(arr[], l, r)
If r > l
1. Find the middle point to divide the array into two halves:
middle m = (l+r)/2
2. Call mergeSort for first half:
Call mergeSort(arr, l, m)
3. Call mergeSort for second half:
Call mergeSort(arr, m+1, r)
4. Merge the two halves sorted in step 2 and 3:
Call merge(arr, l, m, r)
Code Implementation
The three main functions used in the sort are:
This is a device function that takes a pointer to a list of floats, the length of the list, and the number of list elements given to each thread. Puts the list into sorted order in place.
__global__ void Device_Merge(float *d_list, int length, int elementsPerThread){
int my_start, my_end; //indices of each thread's start/end
//Declare counters requierd for recursive mergesort
int left_start, right_start; //Start index of the two lists being merged
int old_left_start;
int left_end, right_end; //End index of the two lists being merged
int headLoc; //current location of the write head on the newList
short current_list = 0; /* Will be used to determine which of two lists is the
most up-to-date */
//allocate enough shared memory for this block's list...
__shared__ float tempList[2][SHARED/sizeof(float)];
//Load memory
int index = blockIdx.x*blockDim.x + threadIdx.x;
for (int i = 0; i < elementsPerThread; i++){
if (index + i < length){
tempList[current_list][elementsPerThread*threadIdx.x + i]=d_list[index + i];
}
}
//Wait until all memory has been loaded
__syncthreads();
//Merge the left and right lists.
for (int walkLen = 1; walkLen < length; walkLen *= 2) {
//Set up start and end indices.
my_start = elementsPerThread*threadIdx.x;
my_end = my_start + elementsPerThread;
left_start = my_start;
while (left_start < my_end) {
old_left_start = left_start; //left_start will be getting incremented soon.
//If this happens, we are done.
if (left_start > my_end){
left_start = len;
break;
}
left_end = left_start + walkLen;
if (left_end > my_end) {
left_end = len;
}
right_start = left_end;
if (right_start > my_end) {
right_end = len;
}
right_end = right_start + walkLen;
if (right_end > my_end) {
right_end = len;
}
solve(&tempList, left_start, right_start , old_left_start, my_start, int my_end, left_end, right_end, headLoc);
left_start = old_left_start + 2*walkLen;
current_list = !current_list;
}
}
__syncthreads();//Wait until all thread completes swapping if not race condition will appear
//as it might update non sorted value to d_list
int index = blockIdx.x*blockDim.x + threadIdx.x;
for (int i = 0; i < elementsPerThread; i++){
if (index + i < length){
d_list[index + i]=subList[current_list][elementsPerThread*threadIdx.x + i];
}
}
__syncthreads();// //Wait until all memory has been loaded
return;
}
This is our host function called by main() function. Takes a pointer to a list of floats.
the length of the list, the number of threads per block, and the number of blocks on which to execute. Allocate space for device copy, copy input to device and Launch a Device_Merge kernel on GPU.
void MergeSort(float *h_list, int len, int threadsPerBlock, int blocks) {
//device copy
float *d_list;
//Allocate space for device copy
cudaMalloc((void **) &d_list, len*sizeof(float));
//copy input to device
cudaMemcpy(d_list, h_list, len*sizeof(float), cudaMemcpyHostToDevice);
int elementsPerThread = ceil(len/float(threadsPerBlock*blocks));
// Launch a Device_Merge kernel on GPU
Device_Merge<<<blocks, threadsPerBlock>>>(d_list, len, elementsPerThread);
cudaMemcpy(h_list, d_list, len*sizeof(float), cudaMemcpyDeviceToHost);
cudaFree(d_list);
}
__device__ solve (void), can only be executed on the device and can only be called from a device or kernel function.
__device__ solve(int **tempList, int left_start, int right_start , int old_left_start, int my_start, int my_end, int left_end, int right_end, int headLoc)
{
for (int i = 0; i < walkLen; i++){
if (tempList[current_list][left_start] < tempList[current_list][right_start]) {
tempList[!current_list][headLoc] = tempList[current_list][left_start];
left_start++;
headLoc++;
//Check if l is now empty
if (left_start == left_end) {
for (int j = right_start; j < right_end; j++){
tempList[!current_list][headLoc] = tempList[current_list][right_start];
right_start++;
headLoc++;
}
}
}
else {
tempList[!current_list][headLoc] = tempList[current_list][right_start];
right_start++;
//Check if r is now empty
if (right_start == right_end) {
for (int j = left_start; j < left_end; j++){
tempList[!current_list][headLoc] = tempList[current_list][right_start];
right_start++;
headLoc++;
}
}
}
}
}
(For complete code press here.)
Performance:
Following programs are checked on Nsight Eclipse. Nsight Eclipse is Eclipse IDE for C/C++ bundled with the libraries of CUDA. These results are checked on a system which has GPU of compute capability of 1.2 (refer to chart for more details about Compute capability versions ).
Sorting 1 million integers
- c++ STL library function execution time
sort()-> 0.738 seconds- My CUDA mergesort, with 512 threads
./mergesort-> 1.871 seconds
While I didn’t really expect to beat the system, sort I was curious what parts of my program took the longest so.
| parse argv | 16 microseconds |
| cudaMemcpy list back to the host | 1.28 seconds |
| cudaMalloc device lists | 122 milliseconds |
| cudaMemcpy list to device | 4.47 milliseconds |
| cudaMalloc metadata | 122 microseconds |
| cudaMemcpy metadata to device | 1.15 milliseconds |
| call mergesort kernel | 39 microseconds |
You could have guessed it, but the most time was spent in IO and after that was just moving memory around. The actual sorting would have taken lesser time, which is not too bad at all.