In this post, we will see how to parallelize Quicksort algorithm using OPENMP.
In Quicksort, an input is any sequence of numbers and output is a Sorted array. QuickSort is a Divide and Conquer algorithm. It picks an element as pivot and partitions the given array around the picked pivot. We start with one number, mostly the first number, and finds its position in the sorted array. Then we divide the array into two parts considering this pivot element’s position in the sorted array. In each part, separately, we find the pivot elements. This process continues until all numbers are processed and we get the sorted array.
/* low --> Starting index, high --> Ending index */
quickSort(arr[], low, high)
{
if (low < high)
{
/* pi is partitioning index, arr[p] is now
at right place */
pi = partition(arr, low, high);
quickSort(arr, low, pi - 1); // Before pi
quickSort(arr, pi + 1, high); // After pi
}
}
In Parallel Quicksort, we divide it into two parts by partitions the given array around the first pivot where each part is processed by independent thread i.e. different threads will find out pivot element in each part recursively and sort the array independently.
Here PE stands for Pivot Element.
int j = partition(arr,0,n-1);
//here j is my first Pivot Element
#pragma omp parallel sections
{
#pragma omp section
{
quicksort(arr,0, j - 1);//Thread 1
}
#pragma omp section
{
quicksort(arr, j + 1, n-1);//Thread2
}
}
if we use #pragma omp parallel section inside quicksort function the total no of threads will be equal to the total no of calls to the quicksort function. The code is correct, but two threads are created and distroyed in each call which creates a lot of overhead which makes it slower than the serial code.
(For complete code press here.)
So we create only two threads instead of creating too many and got the performance gain from the serial version
(For complete code press here.)
The results obtained clearly show that the parallel operations are faster.
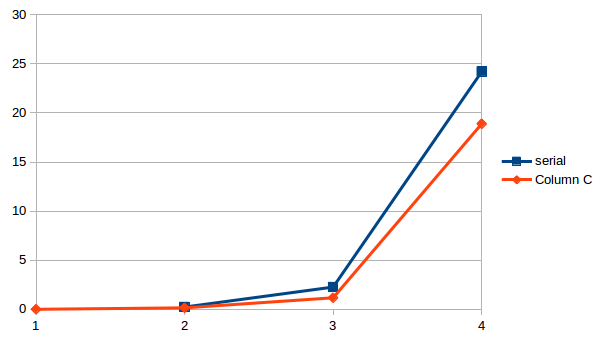
|
Array size |
Serial(in sec) |
Parallel(in sec) |
| 10000 | 0.0024s | 0.0013 |
| 100000 | 0.2300 | 0.1885 |
| 1000000 | 2.26379 | 1.4734 |
| 10000000 | 24.2066 | 18.8934 |
